
{kind=link}
11.1 Introduction: The Four Major Macromolecules
Within all lifeforms on Earth, from the tiniest bacterium to the giant sperm whale, there are four major classes of organic macromolecules that are always found and are essential to life. These are the carbohydrates, lipids (or fats), proteins, and nucleic acids. All of the major macromolecule classes are similar, in that, they are large polymers that are assembled from small repeating monomer subunits. In Chapter 6, you were introduced to the polymers of life and their building block structures, as shown below in Figure 11.1. Recall that the monomer units for building the nucleic acids, DNA and RNA, are the nucleotide bases, whereas the monomers for proteins are amino acids, for carbohydrates are sugar residues, and for lipids are fatty acids or acetyl groups.
This chapter will focus on an introduction to the structure and function of these macromolecules. You will find that the major macromolecules are held together by the same chemical linkages that you’ve been exploring in Chapters 9 and 10, and rely heavily on dehydration synthesis for their formation, and hydrolysis for their breakdown.
You are viewing: Which Macromolecules Contain Phosphorus
Figure 11.1: The Molecular building blocks of life are made from organic compounds.
Modified from: Boghog
Fun Video Tutorial Introducing the Major Macromolecules
Biological Molecules – You Are What You Eat: Crash Course Biology #3.
11.2 Protein Structure and Function
Amino Acids and Primary Protein Structure
The major building block of proteins are called alpha amino acids. As their name implies they contain a carboxylic acid functional group and an amine functional group. The alpha designation is used to indicate that these two functional groups are separated from one another by one carbon group. In addition to the amine and the carboxylic acid, the alpha carbon is also attached to a hydrogen and one additional group that can vary in size and length. In the diagram below, this group is designated as an R-group. Within living organisms there are 20 amino acids used as protein building blocks. They differ from one another only at the R-group postion. The basic structure of an amino acid is shown below:

Figure 11.2 General Structure of an Alpha Amino Acid
Within cellular systems, proteins are linked together by a complex system of RNA and proteins called the ribosome. Thus, as the amino acids are linked together to form a specific protein, they are placed within a very specific order that is dictated by the genetic information contained within the RNA. This specific ordering of amino acids is known as the protein’s primary sequence. The primary sequence of a protein is linked together using dehydration synthesis that combine the carboxylic acid of the upstream amino acid with the amine functional group of the downstream amino acid to form an amide linkage. Within protein structures, this amide linkage is known as the peptide bond. Subsequent amino acids will be added onto the carboxylic acid terminal of the growing protein. Thus, proteins are always synthesized in a directional manner starting with the amine and ending with the carboxylic acid tail. New amino acids are always added onto the carboxylic acid tail, never onto the amine of the first amino acid in the chain. In addition, because the R-groups can be quite bulky, they usually alternate on either side of the growing protein chain in the trans conformation. The cis conformation is only preferred with one specific amino acid known as proline.
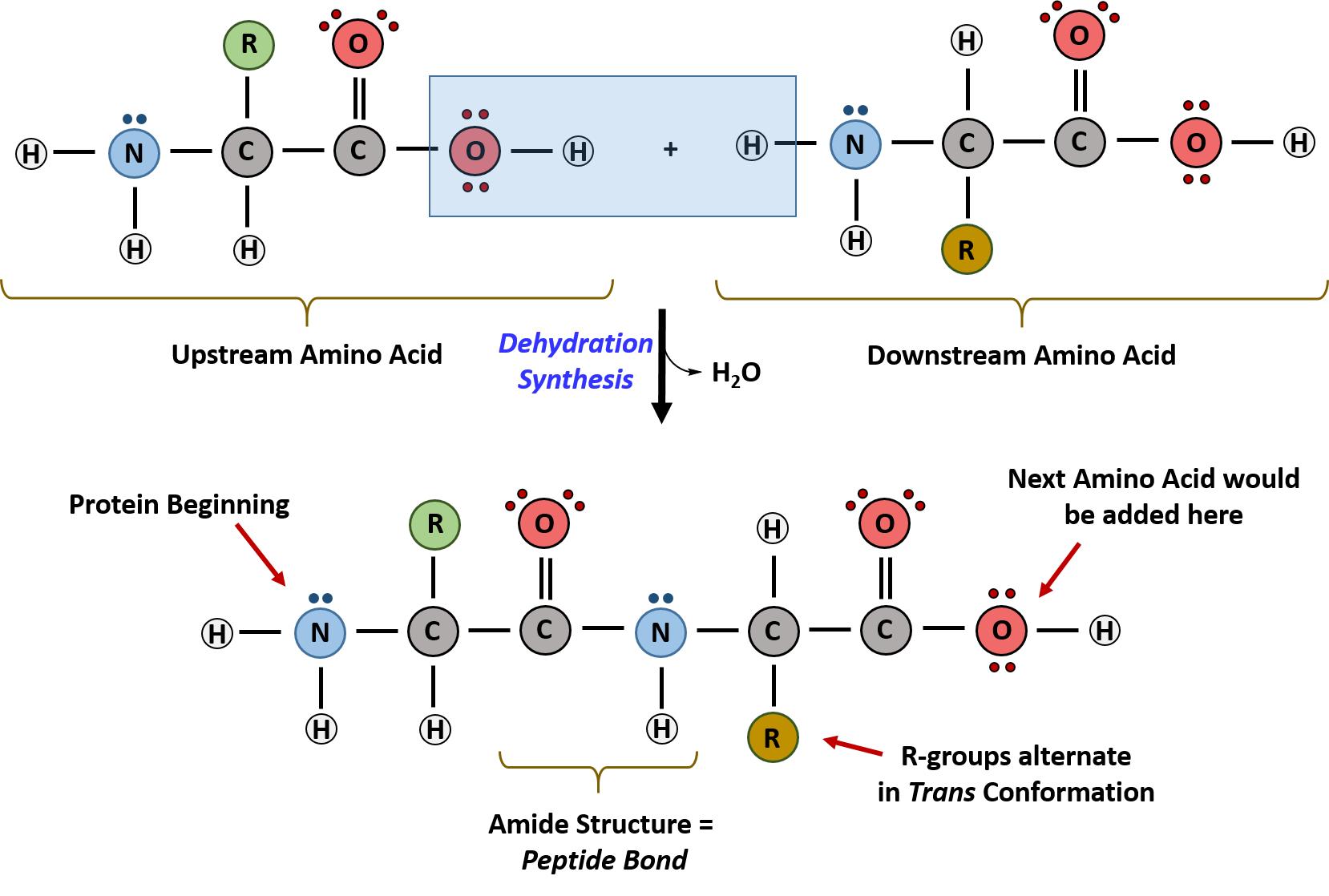
Figure 11.3 Formation of the Peptide Bond. The addition of two amino acids to form a peptide requires dehydration synthesis.
Proteins are very large molecules containing many amino acid residues linked together in very specific order. Proteins range in size from 50 amino acids in length to the largest known protein containing 33,423 amino acids. Macromolecules with fewer than 50 amino acids are known as peptides.
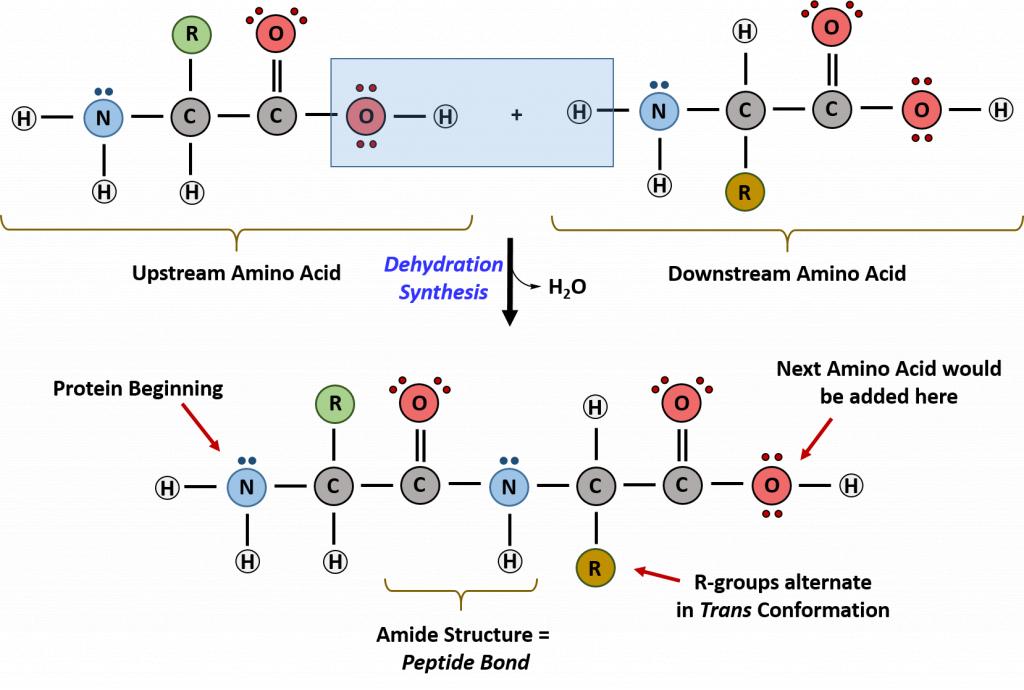
Figure 11.4 Peptides and Proteins are macromolecules built from long chains of amino acids joined together through amide linkages.
The identity and function of a peptide or a protein is determined by the primary sequence of amino acids within its structure. There are a total of 20 alpha amino acids that are commonly incorporated into protein structures (Figure 11.5).

Figure 11.5 Structure of the 20 Alpha Amino Acids used in Protein Synthesis.
Due to the large pool of amino acids that can be incorporated at each position within the protein, there are billions of different possible protein combinations that can be used to create novel protein structures! For example, think about a tripeptide made from this amino acid pool. At each position there are 20 different options that can be incorporated. Thus, the total number of resulting tripeptides possible would be 20 X 20 X 20 or 203, which equals 8,000 different tripeptide options! Now think about how many options there would be for a small peptide containing 40 amino acids. There would be 2040 options, or a mind boggling 1.09 X 1052 potential sequence options! Each of these options would vary in the overall protein shape, as the nature of the amino acid side chains helps to determine the interaction of the protein with the other residues in the protein itself and with its surrounding environment. Thus, it is useful to learn a little bit about the general characteristics of the amino acid side chains.
Read more : Which Fish Good For Diabetes
The different amino acid side chains can be grouped into different classes based on their chemical properties (Figure 11.5). For example, some amino acid side chains only contain carbon and hydrogen and are thus, very nonpolar and hydrophobic. Others contain electronegative functional groups with oxygen or nitrogen and can form hydrogen bonds forming more polar interactions. Still others contain carboxylic acid functional groups and can act as acids or they contain amines and can act as bases, forming fully charged molecules. The character of the amino acids throughout the protein help the protein to fold and form its 3-dimentional structure. It is this 3-D shape that is required for the functional activity of the protein (ie. protein shape = protein function). For proteins found inside the watery environments of the cell, hydrophobic amino acids will often be found on the inside of the protein structure, whereas water-loving hydrophilic amino acids will be on the surface where they can hydrogen bond and interact with the water molecules. Proline is unique because it has the only R-group that forms a cyclic structure with the amine functional group in the main chain. This cyclization is what causes proline to adopt the cis conformation rather than the trans conformation within the backbone. This shift is structure will often mean that prolines are positions where bends or directional changes occur within the protein. Methionine is unique, in that it serves as the starting amino acid for almost all of the many thousands of proteins known in nature. Cysteines contain thiol functional groups and thus, can be oxidized with other cysteine residues to form disulfide bonds within the protein structure (Figure 11.6). Disulfide bridges add additional stability to the 3-D structure and are often required for correct protein folding and function (Figure 11.6).
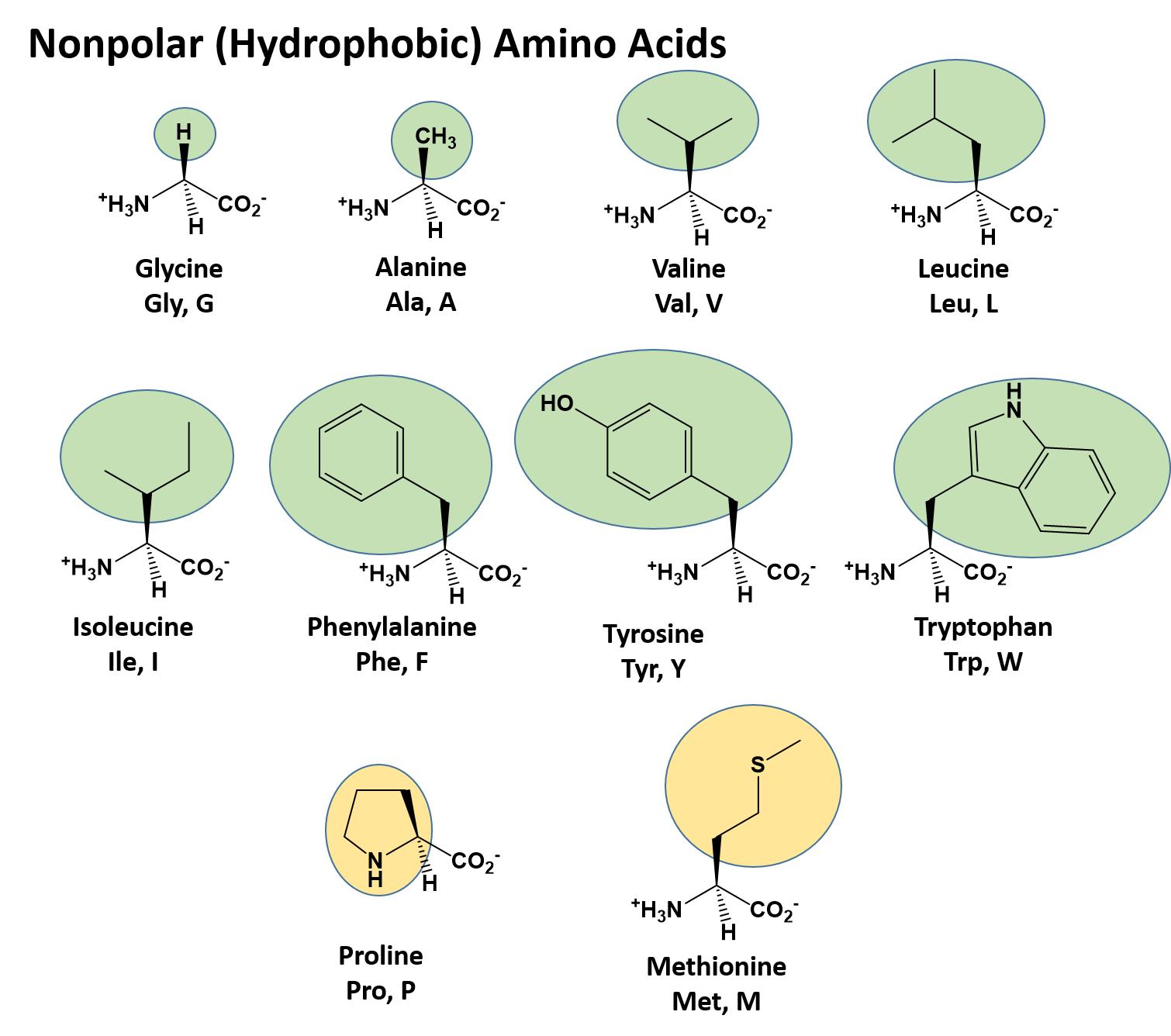
Figure 11.6 Disulfide Bonds. Disulfide bonds are formed between two cysteine residues within a peptide or protein sequence or between different peptide or protein chains. In the example above the two peptide chains that form the hormone insulin are depicted. Disulfide bridges between the two chains are required for the proper function of this hormone to regulate blood glucose levels.
Protein Shape and Function
The primary structure of each protein leads to the unique folding pattern that is characteristic for that specific protein. Recall that this is the linear order of the amino acids as they are linked together in the protein chain (Figure 11.7).
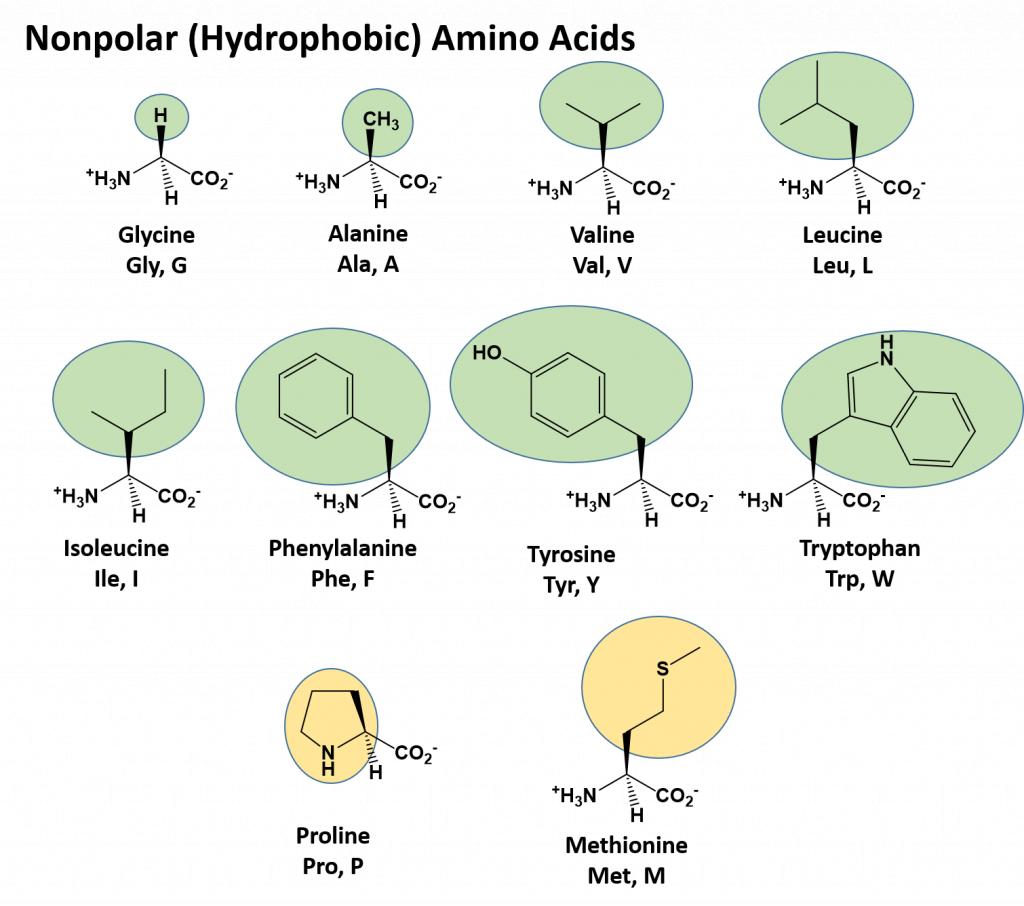
Figure 11.7 Primary protein structure is the linear sequence of amino acids.
(credit: modification of work by National Human Genome Research Institute)
Within each protein small regions may adopt specific folding patterns. These specific motifs or patterns are called secondary structure. Common secondary structural features include alpha helix and beta-pleated sheet (Figure 11.8). Within these structures, intramolecular interactions, especially hydrogen bonding between the backbone amine and carbonyl functional groups are critical to maintain 3-dimensional shape. Every helical turn in an alpha helix has 3.6 amino acid residues. The R groups (the variant groups) of the polypeptide protrude out from the α-helix chain. In the β-pleated sheet, the “pleats” are formed by hydrogen bonding between atoms on the backbone of the polypeptide chain. The R groups are attached to the carbons and extend above and below the folds of the pleat. The pleated segments align parallel or antiparallel to each other, and hydrogen bonds form between the partially positive nitrogen atom in the amino group and the partially negative oxygen atom in the carbonyl group of the peptide backbone. The α-helix and β-pleated sheet structures are found in most proteins and they play an important structural role.
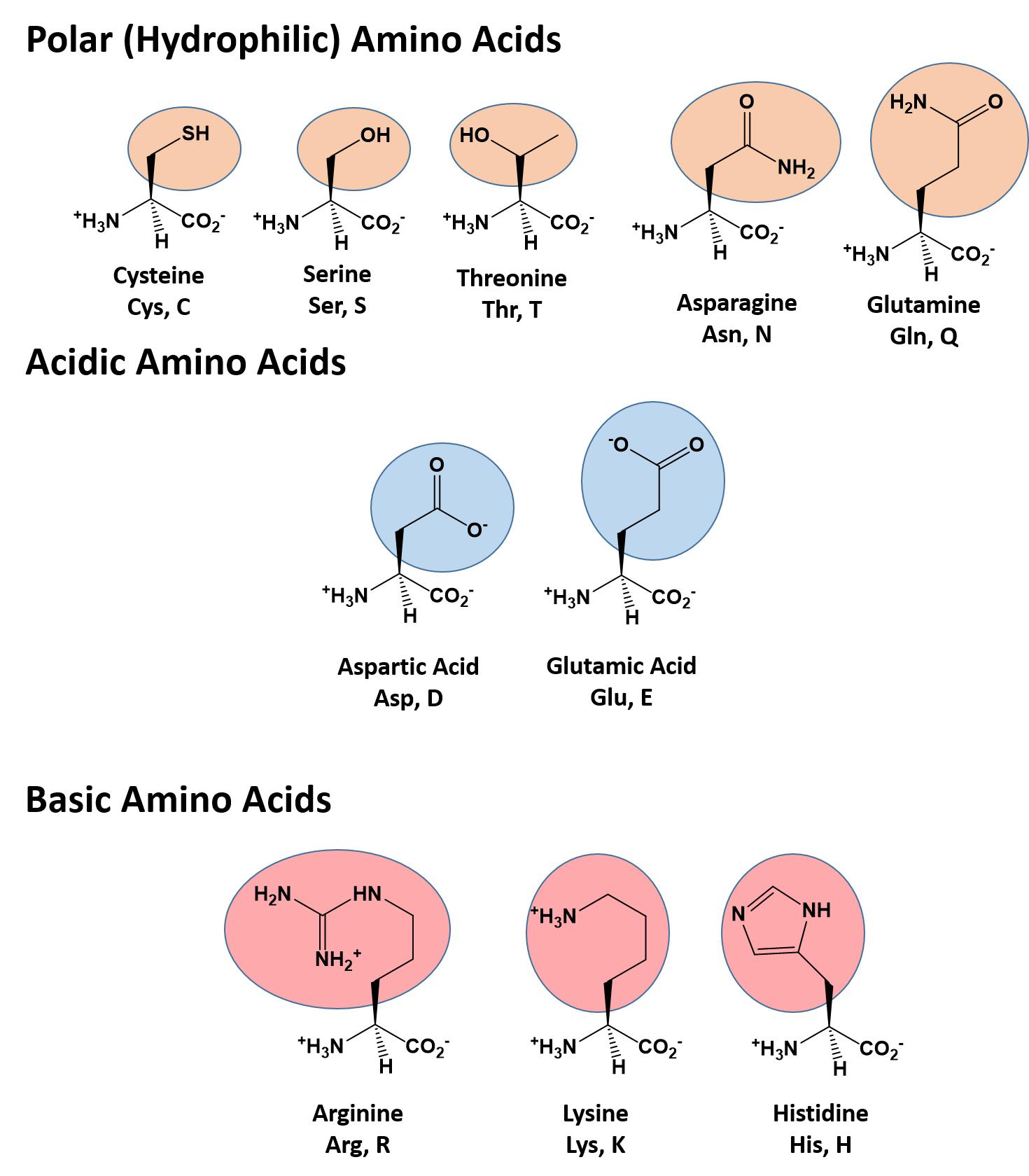
Figure 11.8 Secondary Structural Features in Protein Structure. The alpha helix and beta-pleated sheet are common structural motifs found in most proteins. They are held together by hydrogen bonding between the amine and the carbonyl oxygen within the amino acid backbone.
A Closer Look: Secondary Protein Structure in Silk
There were many trade routes throughout the ancient world. The most highly traveled and culturally significant of these was called the Silk Road. The Silk Road ran from the Chinese city of Chang’an all the way through India and into the Mediterranean and Egypt. The reason that the Silk road was so culturally significant was because of the great distance that it covered. Essentially the entire ancient world was connected by one trade route.
Figure 11.9 Silkworms
On the route many things were traded, including silk, spices, slaves, ideas, and gun powder. The silk road had an astounding effect on the creation of many societies. It was able to bring economic wealth into areas along the route, and new ideas traveled the distance and influence many things including art. An example of this is Buddhist art that was found in India. The painting has many western influences that can be identified in it, such as realistic musculature of the people being painted. Also, the trade of gun powder to the West helped influence warfare, and in turn shaped the modern world. The real reason the Silk Road was started though was for the product that it takes its name from: Silk.
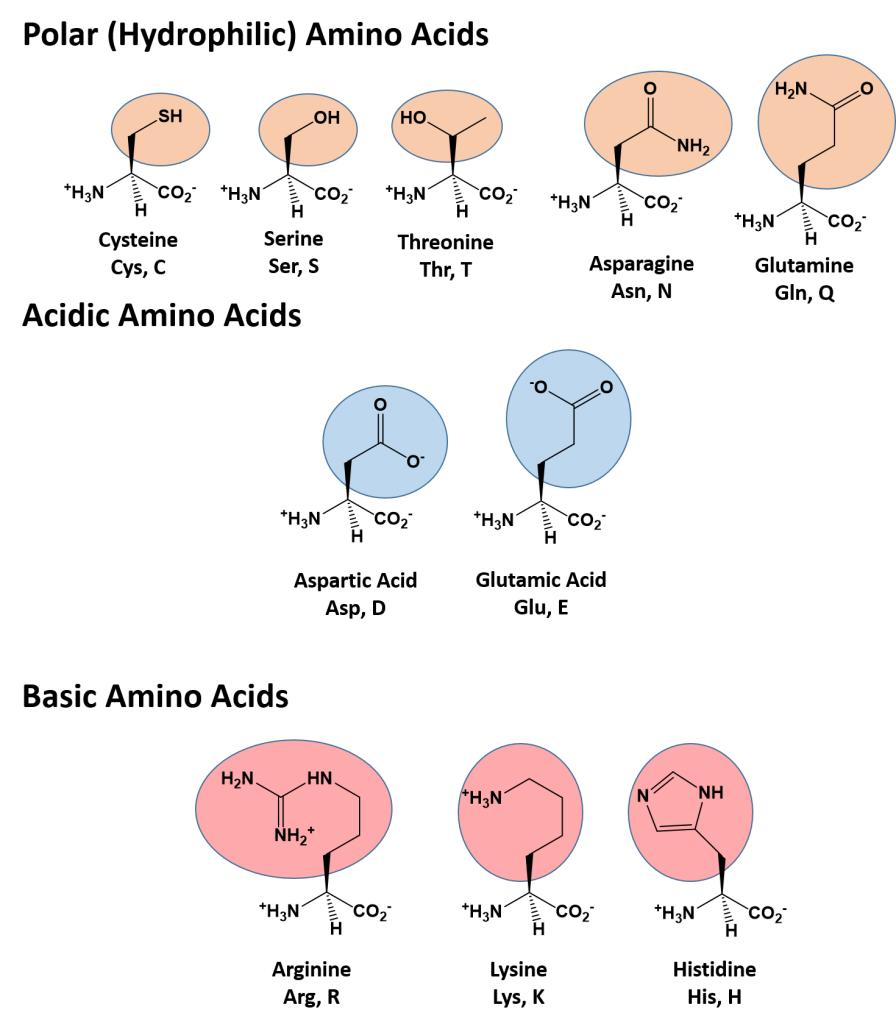
Figure 11.10 Land route in Red, Sea route in Blue
Silk was prized by the Kings and Queens of both European and Middle Eastern Society. The Silk showed that the rulers had power and wealth because the silk was not easy to come by, and therefore was definitely not cheap. Silk was first developed in China, and is made by harvesting the silk from the cocoons of the mulberry silkworm. The silk itself is called a natural protein fiber because it is composed of a pattern of amino acids in a secondary protein structure. The secondary structure of silk is the beta pleated sheet. The primary structure of silk contains the amino acids of glycine, alanine, serine, in specific repeating pattern. These three amino acids make up 90% of the protein in silk. The last 10% is comprised of the amino acids glutamic acid, valine, and aspartic acid. These amino acids are used as side chains and affect things such as elasticity and strength. they also vary between various species. The beta pleated sheet of silk is connected by hydrogen bonds. The hydrogen bonds in the silk form beta pleated sheets rather than alpha helixes because of where the bonds occur. The hydrogen bonds go from the amide hydrogens on one protein chain to the corresponding carbonyl oxygen across the way on the other protein chain. This is in contrast to the alpha helix because in that structure the bonds go from the amide to the carbonyl oxygen, but they are not adjacent. The carbonyl oxygen is on the amino acid that is four residues before.
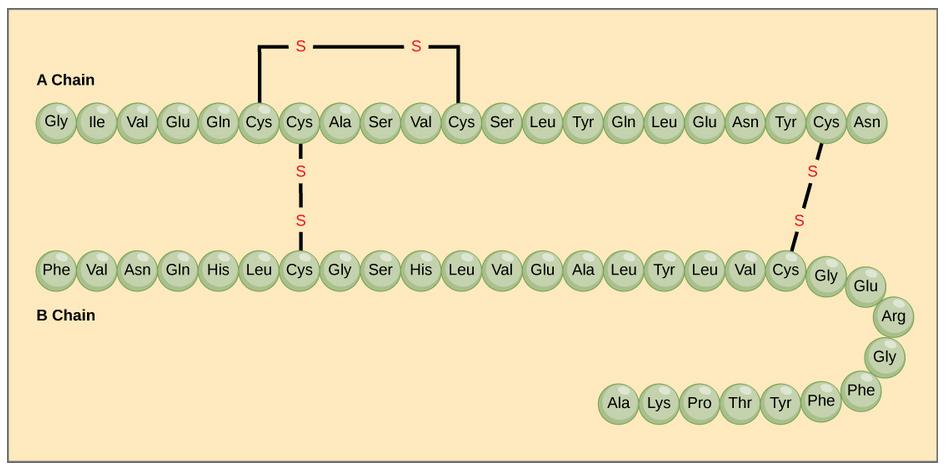
Figure 11.11 Parallel and Antiparallel Beta-Pleated Sheets
Read more : Which Targeting Options Are A Good Fit For Amanda’s Campaign
Silk is a great example of the beta pleated sheet structure. The formation of this secondary structure in the silk protein allows it to have very strong tensile strength. Silk also helped to form one of the greatest trading routes in history, allowing for the exchange of ideas, products and cultures while advancing the societies that were involved. Silk contains both anti-parallel and parallel arrangements of beta sheets. Unlike the α helix, though, the side chains are squeezed rather close together in a pleated-sheet arrangement. In consequence very bulky side chains make the structure unstable. This explains why silk is composed almost entirely of glycine, alanine, and serine, the three amino acids with the smallest side chains. Some species of silk worm produce varying amounts of bulky side chains, but these silks are not as prized as the mulberry silkworm (which has no bulky amino acid side chains) because the silk with bulky side chains is weaker and doesn’t have as much tensile strength.
The complete 3-dimensional shape of the entire protein (or sum of all the secondary structures) is known as the tertiary structure of the protein and is a unique and defining feature for that protein (Figure 11.12). Primarily, the interactions among R groups creates the complex three-dimensional tertiary structure of a protein. The nature of the R groups found in the amino acids involved can counteract the formation of the hydrogen bonds described for standard secondary structures. For example, R groups with like charges are repelled by each other and those with unlike charges are attracted to each other (ionic bonds). When protein folding takes place, the hydrophobic R groups of nonpolar amino acids lay in the interior of the protein, whereas the hydrophilic R groups lay on the outside. The former types of interactions are also known as hydrophobic interactions. Interaction between cysteine side chains forms disulfide linkages in the presence of oxygen, the only covalent bond forming during protein folding.
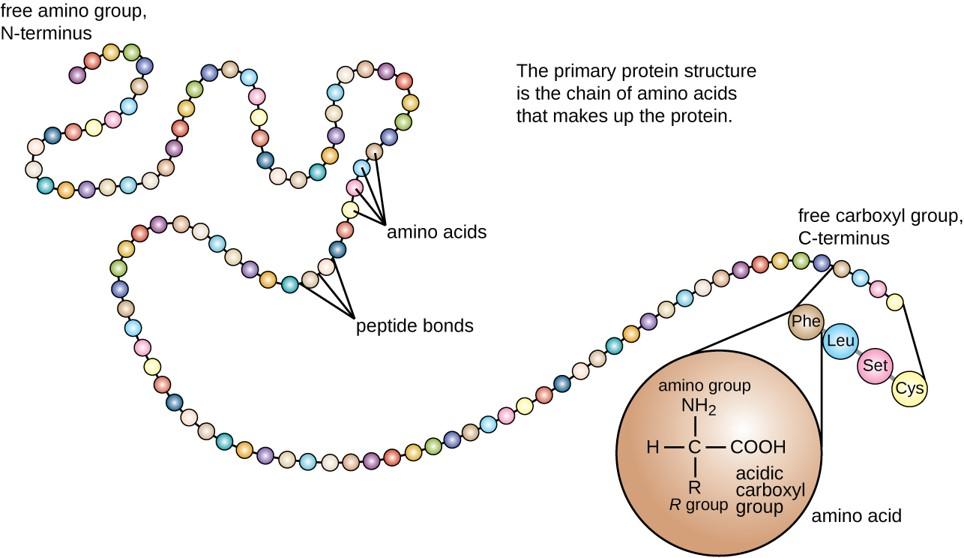
Figure 11.12 Tertiary Protein Structure. The tertiary structure of proteins is determined by a variety of chemical interactions. These include hydrophobic interactions, ionic bonding, hydrogen bonding and disulfide linkages.
All of these interactions, weak and strong, determine the final three-dimensional shape of the protein. When a protein loses its three-dimensional shape, it is usually no longer be functional.
In nature, some proteins are formed from several polypeptides, also known as subunits, and the interaction of these subunits forms the quaternary structure. Weak interactions between the subunits help to stabilize the overall structure. For example, insulin (a globular protein) has a combination of hydrogen bonds and disulfide bonds that cause it to be mostly clumped into a ball shape. Insulin starts out as a single polypeptide and loses some internal sequences during cellular processing that form two chains held together by disulfide linkages as shown in figure 11.6. Three of these structures are then grouped further forming an inactive hexamer (Figure 11.13). The hexamer form of insulin is a way for the body to store insulin in a stable and inactive conformation so that it is available for release and reactivation in the monomer form.
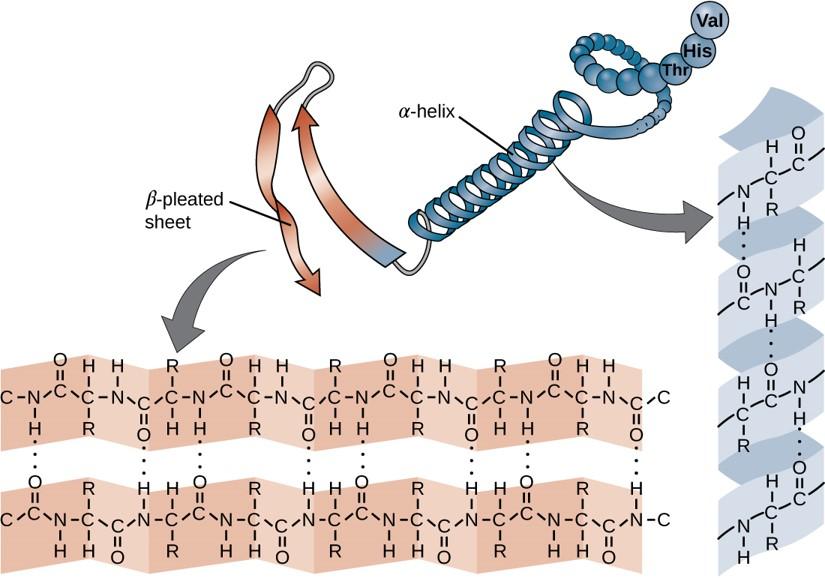
Figure 11.13 The Insulin Hormone is a Good Example of Quaternary Structure. Insulin is produced and stored in the body as a hexamer (a unit of six insulin molecules), while the active form is the monomer. The hexamer is an inactive form with long-term stability, which serves as a way to keep the highly reactive insulin protected, yet readily available.
Figure By: Isaac Yonemoto
The four levels of protein structure (primary, secondary, tertiary, and quaternary) are summarized in Figure 11.14.
Figure 11.14 The four levels of protein structure can be observed in these illustrations. (credit: modification of work by National Human Genome Research Institute)
Hydrolysis is the breakdown of the primary protein sequence by the addition of water to reform the individual amino acids monomer units.
Figure 11.15 Hydrolysis of Proteins. In the hydrolysis reaction, water is added across the amide bond incorporating the -OH group with the carbonyl carbon and reforming the carboxylic acid. The hydrogen from the water reforms the amine.
If the protein is subject to changes in temperature, pH, or exposure to chemicals, the protein structure may unfold, losing its shape without breaking down the primary sequence in what is known as denaturation (Figure 11.16). Denaturation is different from hydrolysis, in that the primary strcture of the protein is not affected. Denaturation is often reversible because the primary structure of the polypeptide is conserved in the process if the denaturing agent is removed, allowing the protein to refold and resume its function. Sometimes, however, denaturation is irreversible, leading to a permanent loss of function. One example of irreversible protein denaturation is when an egg is fried. The albumin protein in the liquid egg white is denatured when placed in a hot pan. Note that not all proteins are denatured at high temperatures; for instance, bacteria that survive in hot springs have proteins that function at temperatures close to boiling. The stomach is also very acidic, has a low pH, and denatures proteins as part of the digestion process; however, the digestive enzymes of the stomach retain their activity under these conditions.
Figure 11.16 Protein Denaturation. Figure (1) depicts the correctly folded intact protein. Step (2) applies heat to the system that is above the threshold of maintaining the intramolecular protein interactions. Step (3) shows the unfolded or denatured protein. Colored regions in the denatured protein correspond to the colored regions of the natively folded protein shown in (1).
Diagram provided by: Scurran15
Protein folding is critical to its function. It was originally thought that the proteins themselves were responsible for the folding process. Only recently was it found that often they receive assistance in the folding process from protein helpers known as chaperones (or chaperonins) that associate with the target protein during the folding process. They act by preventing aggregation of polypeptides that make up the complete protein structure, and they disassociate from the protein once the target protein is folded.
Proteins are involved in many cellular functions. Proteins can act as enzymes which enhance the rate of chemical reactions. In fact, 99% of enzymatic reactions within a cell are mediated by proteins. Thus, they are integral in the processes of building up or breaking down of cellular components. Proteins can also act as structural scaffolding within the cell, helping to maintain cellular shape. Proteins can also be involved in cellular signaling and communication, as well as the transport of molecules from one location to another. Under extreme circumstances such as starvation, proteins can also be used as an energy source within the cell.
Source: https://t-tees.com
Category: WHICH