
{kind=link}
What are pre-trained embeddings and why?
Pre-trained word embeddings are vector representation of words trained on a large dataset. With pre-trained embeddings, you will essentially be using the weights and vocabulary from the end result of the training process done by….someone else! (It could also be you)
One benefit of using pre-trained embeddings is that you can hit the ground running without the need for finding a large text corpora which you will have to preprocess and train with the appropriate settings.
You are viewing: How To Load Glove In Gensim

Another benefit is the savings in training time. Training on a large corpora could demand high computation power and long training times which may not be something that you want to afford for quick experimentation.
If you want to avoid all of these logistics but still have access to good quality embeddings, you could use pre-trained word embeddings trained on a dataset that fits the domain you are working in.
For example, if you are working with news articles, it may be perfectly fine to use embeddings trained on a Twitter dataset as there is ongoing discussion about current issues as well as a constant stream of news related Tweets.
Accessing pre-trained embeddings is extremely easy with Gensim as it allows you to use pre-trained GloVe and Word2Vec embeddings with minimal effort. The code snippets below show you how.
Here’s the working notebook for this tutorial.
Accessing pre-trained Twitter GloVe embeddings
Here, we are trying to access GloVe embeddings trained on a Twitter dataset. This first step downloads the pre-trained embeddings and loads it for re-use. These vectors are based on 2B tweets, 27B tokens, 1.2M vocab, uncased. The original source of the embeddings can be found here: https://nlp.stanford.edu/projects/glove/. The 25 in the model name below refers to the dimensionality of the vectors.
# download the model and return as object ready for use model_glove_twitter = api.load(“glove-twitter-25”)
Once you have loaded the pre-trained model, just use it as you would with any Gensim Word2Vec model. Here are a few examples:
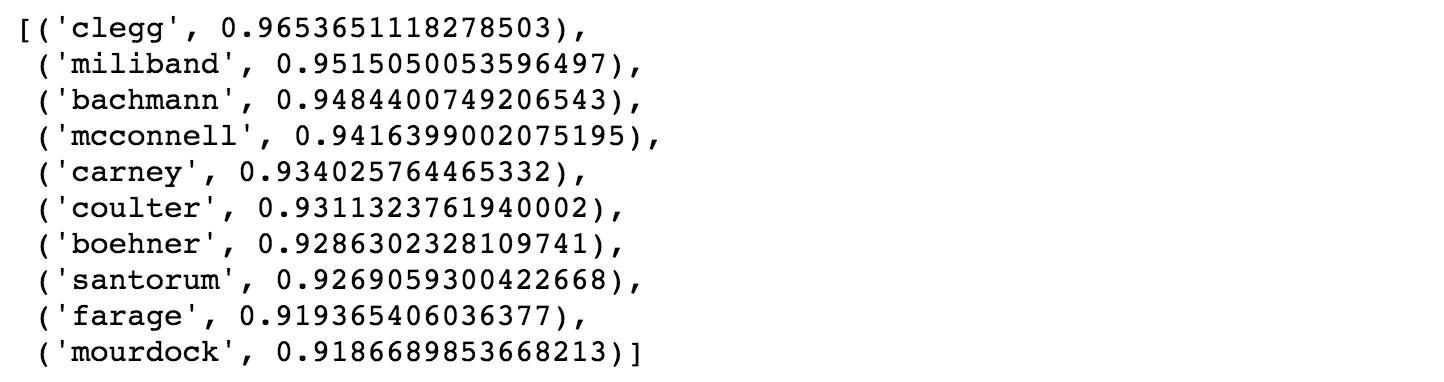
# get similar items model_glove_twitter.wv.most_similar(“pelosi”,topn=10)

# get similar items model_glove_twitter.wv.most_similar(“policies”,topn=10)
#what doesn’t fit? model_glove_twitter.wv.doesnt_match([“trump”,”bernie”,”obama”,”pelosi”,”orange”])
This next example prints the word vectors for trump and obama.
# show weight vector for trump model_glove_twitter[‘trump’],model_glove_twitter[‘obama’]
Notice that it prints only 25 values for each word. This is because our vector dimensionality is 25. For vectors of other dimensionality use the appropriate model names from here or reference the gensim-data GitHub repo:
- glove-twitter-25 (104 MB)
- glove-twitter-50 (199 MB)
- glove-twitter-100 (387 MB)
- glove-twitter-200 (758 MB)
Accessing pre-trained Wikipedia GloVe embeddings
The GloVe embeddings below was trained on an English Wikipedia dump and English Gigaword 5th Edition dataset. Its dimensionality is 100 and has 6B tokens (uncased). The original source of the embeddings can be found here: https://nlp.stanford.edu/projects/glove/
#again, download and load the model model_gigaword = api.load(“glove-wiki-gigaword-100”)
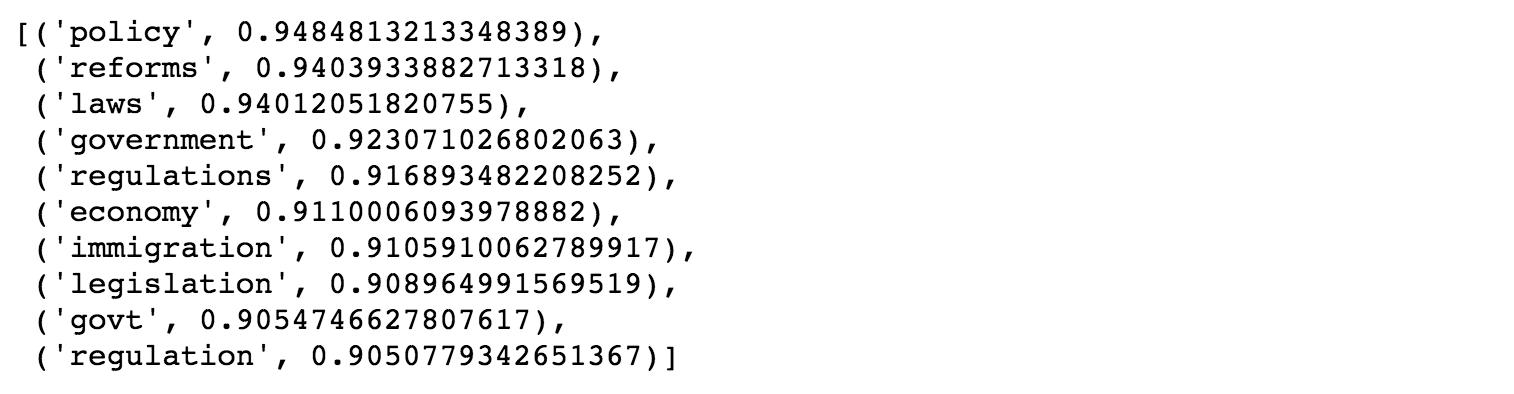
Once you have loaded the pre-trained model, just use it as usual. Here is a similarity example:
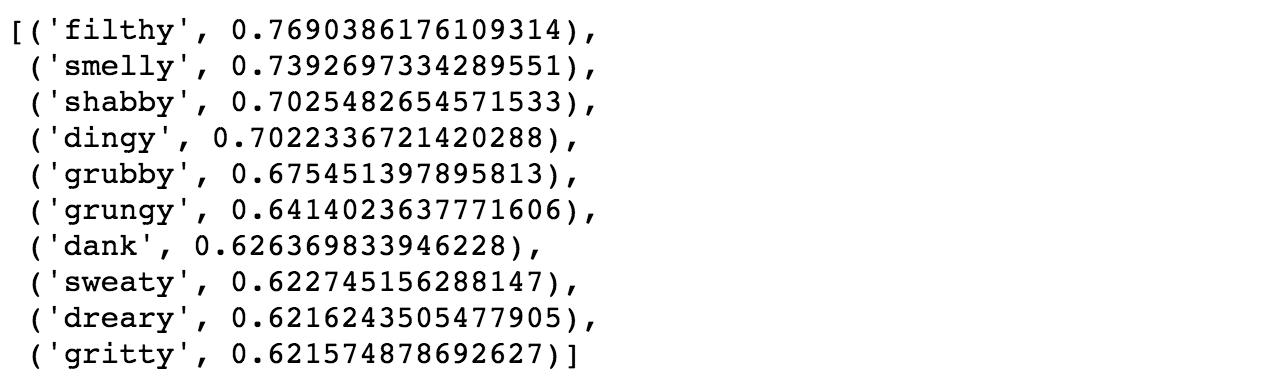
# find similarity model_gigaword.wv.most_similar(positive=[‘dirty’,’grimy’],topn=10)

For vectors of other dimensionality you can use the appropriate model names from below or reference the gensim-data repository :
- glove-wiki-gigaword-50 (65 MB)
- glove-wiki-gigaword-100 (128 MB)
- gglove-wiki-gigaword-200 (252 MB)
- glove-wiki-gigaword-300 (376 MB)
Accessing pre-trained Word2Vec embeddings
So far, you have looked at a few examples using GloVe embeddings. In the same way, you can also load pre-trained Word2Vec embeddings. Here are some of your options for Word2Vec:
- word2vec-google-news-300 (1662 MB) (dimensionality: 300)
- word2vec-ruscorpora-300 (198 MB) (dimensionality: 300)
Be warned that the google news embeddings is sizable, so ensure that you have sufficient disk space before using it.
What can you use pre-trained word embeddings for?
Read more : How Many Tourists Come For The Golden Gloves
You can use pre-trained word embeddings for a variety of tasks including:
- Finding word or phrase similarities
- As feature weights for text classification
- For creating an embedding layer for neural network based text classification
- For machine translation
- Query expansion for search enhancements
- To create sentence embeddings through vector averaging
The possibilities are actually endless, but you may not always get better results than just a bag-of-words approach. For example, I’ve tried sentence embeddings for a search reranking task and the rankings actually deteriorated. The only way to know if it helps, is to try it and see if it improves your evaluation metrics!
Example of using GloVe embeddings to rank phrases by similarity
Here is an example of using the glove-twitter-25 GloVe embeddings to find phrases that are most similar to the query phrase.
Let’s say we have the following phrases and a corresponding query phrase with several misspellings (missing ‘r’ in barack and ‘a’ instead of ‘e’ in hussein).
#possible phrases phrases=[“barrack obama”,”barrack h. obama”,”barrack hussein obama”,”michelle obama”,”donald trump”,”melania trump”] #query phrases with misspellings query=”barack hussain obama”
The goal here is given the query phrase, rank all other phrases by semantic similarity (using the glove twitter embeddings) and compare that with surface level similarity using the jaccard similarity index. Jaccard has no notion of semantics so it sees a token as is.
# compute similarities with query for p in phrases: tokens_1=[t for t in p.split() if t in model.wv.vocab] tokens_2=[t for t in query.split() if t in model.wv.vocab] #compute jaccard similarity jaccard=compute_jaccard(tokens_1,tokens_2) results_jaccard.append([p,jaccard]) #compute cosine similarity using word embedings cosine=0 if (len(tokens_1) > 0 and len(tokens_2)>0): cosine=model_glove_twitter.wv.n_similarity(tokens_1,tokens_2) results_glove.append([p,cosine])
The code above splits each candidate phrase as well as the query into a set of tokens (words). The n_similarity(tokens_1,tokens_2) takes the average of the word vectors for the query (tokens_2) and the phrase (tokens_1) and computes the cosine similarity using the resulting averaged vectors. The results are later sorted by descending order of cosine similarity scores.
This method of vector averaging assumes that the words within tokens_1 share a common concept which is amplified through word averaging. The same is the case for, tokens_2. As pointed out by Radim (creator of Gensim), this crude method works surprisingly well.
Below, you will see the ranking of phrases using the word embeddings method vs. the surface similarity method with Jaccard.
Notice that even with misspellings, we are able to produce a decent ranking of most similar phrases using the GloVe vectors. This is because misspellings are common in tweets. If a misspelled word is present in the vocabulary, then it will have a corresponding weight vector.
In comparison, Jaccard similarity does slightly worse (visually speaking) as all it knows are the tokens given to it and is ignorant to misspellings, nor does it have any notion of semantics.
I hope this article and accompanying notebook will give you a quick start in using pre-trained word embeddings. Can you think of any other use cases for how you would use these embeddings? Leave a comment below with your ideas!
See Also: Word2Vec: A Comparison Between CBOW, Skip-Gram and Skip-GramSI
Recommended Reading
- How to train a word2vec model with Gensim?
- How to incorporate phrases to train a Word2Vec model?
- Comparison between CBOW, Skip-Gram and Skip-GramSI
Resources
- Working notebook for this tutorial
Source: https://t-tees.com
Category: HOW