
{kind=link}

Privacy vs. confidentiality, how do they differ and what do they protect us from?
One of the possible definitions of privacy is the right all people have to control information about oneself, and especially who can access and under what conditions. In many cases privacy is a concept that is intertwined with security; however, security is a much broader concept that encompasses different mechanisms.
You are viewing: Why Is Anonymization A Challenge Of Cybersecurity
Security provides us with tools to help us to protect privacy. One of the most commonly used security techniques to protect information is data encryption, which allows us to protect our information from unauthorized access. So, if when encrypting I am protecting my data and the access, is not enough?
One of the reasons the answer to this question is “no” is that, in many cases, metadata information is unprotected. For example, we can encrypt the content of an email and protect the message, but to send it is needed to include the destination address. If the email sent is directed, for example, to a political party, it would be revealing sensitive information despite having protected the content of the message.
On the other hand, there are certain scenarios where we cannot encrypt information. For example, if we want to outsource the processing of a database or release it for third parties to carry out analyses or studies for statistical purposes. In such scenarios we often find the problem that the database contains a large amount of personal or sensitive information, and even if we remove personal identifiers (for example, the name or passport number), it may not be sufficient to protect the privacy of individuals.
Anonymity, protecting our privacy
Anonymity is a set of techniques that protect privacy by modifying data (including its elimination). What is sought with this technique is to alter the data in such a way that, even if they are subsequently processed by third parties, the identity or certain sensitive attributes of the persons whose data are being processed cannot be revealed.
The management of privacy is regulated by the General Data Protection Regulation (GDPR), the new European regulation that seeks to regulate the processing of our personal data [1]. This regulation establishes that the data must be subject to the appropriate guarantees, minimizing the personal data. Among the measures mentioned in the regulation appears pseudonymization, which consists on substituting a unique ID (as a passport number) by a different value, also unique. Although this mechanism offers certain guarantees of privacy, it has been demonstrated that its level of protection is insufficient in many scenarios, since it is possible to identify a person whose data have been pseudonymized [2].
Anonymity, however, offers much greater protection guarantees than pseudonymization, since its ultimate goal is that anonymised data cannot be associated back to the identity of the people to which they belong. In addition, the GDPR indicates that, whenever possible, the necessary technologies will be used to reduce the risk of identification. Anonymization is one of these technologies.
Main techniques of data anonymity
To anonymize the data correctly the first step is to analyse how the structure of the database to which we want to give access to third parties and to classify the data into three categories:
- Sensitive data: data that have a certain value, on which we will want to draw conclusions in a later analysis (medical condition, salaries, etc.).
- Identifiers: are those fields of the database that allow to identify a person in a unique way, such as DNI, mobile phone …
- Quasi-identifiers: all other data, that is, those personal data that are not identifiers, and that have no special value for our analysis. Quasi-identifiers alone do not reveal information, but when combined with each other or with other external data sources, they may reveal our identity.
The quasi-identifiers are especially relevant to our analysis, since these are the data that we will alter to protect the privacy of the people. It is also important to note that the quasi-identifiers will not be the same in all use cases, since they will depend on the analysis that we want to do later with the data.
Once the data have been classified, different anonymization techniques will be applied to them:
- Generalization: is to add data that have a similar semantic meaning in other classes with a less specific value.
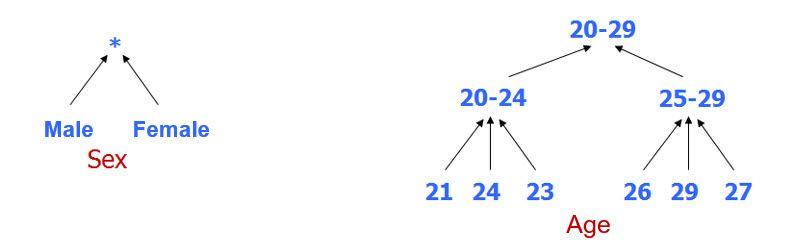
- Randomization: technique that involves applying a random modification to the data. Two main mechanisms are used:
- Noise Injection: It introduces disturbances in the data making them less precise.
- Permutations: randomize associations between attributes, without changing values.
- Deletion: consists of completely eliminating an attribute or a record.
Read more : Why Are People Turning Off Their Phones Tomorrow
There are different approaches to anonymization based on the generalization of attributes. k-anonymity [3] seeks that each person in the database is indistinguishable from at least other k-1 individuals who are also in the database. Starting from k-anonimity other more restrictive approaches emerge. An example is l-diversity [4] which forces the existence of at least l different values of sensitive data in each equivalence class established by k-anonymity. Another example is t-closeness [5], which seeks to generalize the data so that the distribution of quasi-identifiers in each equivalence class is similar to the original data distribution.
In some cases it is not desired to anonymize or publish a complete data set, but rather to protect privacy by anonymizing the results of queries to it. Thus, the technique known as differential privacy [6] consists of introducing noise into the responses, protecting the privacy of the subjects present in the data.
What risks does anonymity protect us from?
As we have seen, in spite of having eliminated the identifiers of a database, in many cases the combination of several attributes would allow us to identify equally to the person to which the data belong. For example, 87% of the US population is identifiable using only their zip code, date of birth, and gender [3]; however, identification is not the only risk that anonymization protects us from:
- Singling out: the aim is to be able to re-identify a person in the anonymised database
- Linkability: It is related that two data records belong to the same person, although no one knows exactly who
- Inference: a sensitive value is deduced from another set of data
Anonymity challenges
It is important to note that there is no single anonymity, and the techniques to be used will vary according to how our data is, what we want to do with it and what privacy requirements we have.
By anonymizing the data, some of the information they contain is lost and, therefore, its usefulness is diminished. The main challenge of anonymization is therefore to maintain an appropriate balance between the level of privacy and utility of the data.

So far we have seen that if we have a personal database, we should not give access to third parties to study them without having previously applied any measures to protect the information. We have also seen that using pseudonyms is not enough, and that anonymization offers generally better guarantees of privacy. But if we anonymize our data then, what can go wrong?
Anonimity is not a simple or straightforward technique and good anonymization depends on a large number of factors.
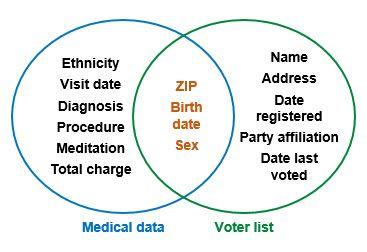
An example of this is the case of an insurance group from Massachusetts that in the 1990s decided to publish the visits of state employees to hospitals, previously anonymised. The database contained about 135,000 records. The governor of Massachusetts said that since the names, addresses and social security numbers had been removed, the identity of the patients was completely protected. However, one student demonstrated that he was able to identify the governor’s hospital records, using only his date of birth, sex, and zip code. Crossing the database with the list of voters (public in the United States), he found that in the city where the governor lived, only 6 people had the same date of birth as he; 3 of them were men; and only 1 lived in the same zip code [3]. In this way it proved that data that may seem anonymous to the naked eye, need not necessarily be.
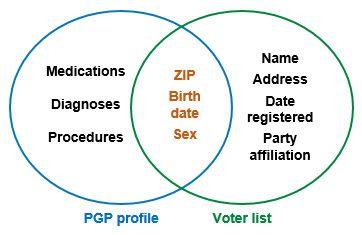
Another case is that of the Personal Genome Project in 2013. The data of the participants were theoretically anonymous, as their names and addresses were deleted from the profiles, but information such as medical information, genomic information, date of birth, sex, and Postal Code. Using this data and the same list of voters from the previous scenario, a group of experts in privacy was able to reveal the identity of between 84 and 97% of published profiles [7].
How Gradiant can help industry
Read more : Why Did Saul Want To Kill David
Gradiant works on the design and development of new anonymising mechanisms, which simultaneously offer the best guarantees of privacy and usefulness for the data. Our solutions allow:
- Measure the level of privacy of anonymised and non-anonymised data
- Improve existing anonymization processes
- Measure loss of utility of anonymised data
- Automate data anonymization processes
These developments and technologies are applicable in different fields. Through their use with banking data, for example, they have made it possible to outsource calculations of credit card fraud detection or risk assessment models in loans, while ensuring the protection of the privacy of user data.
Proyecto WITDOM
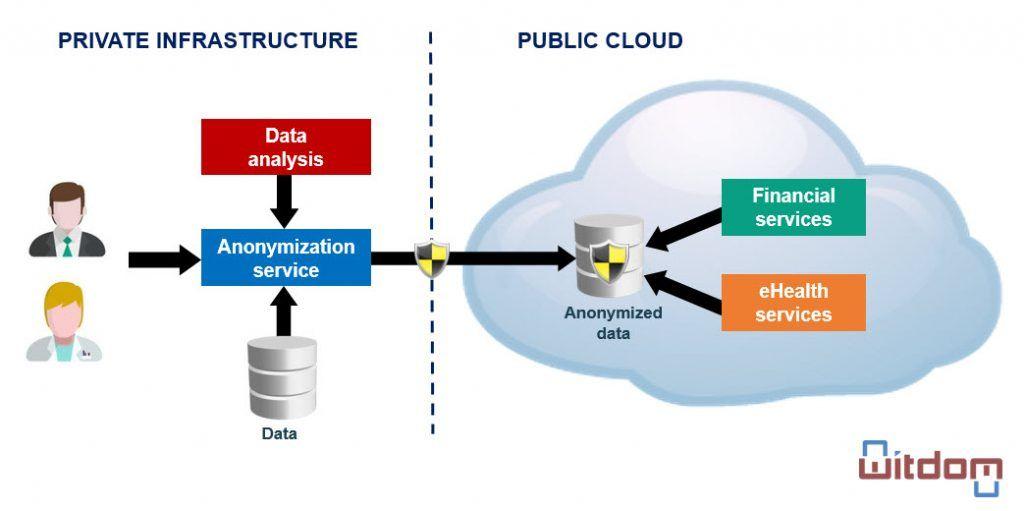
WITDOM is an H2020 project whose objective is the generation of a framework that allows to protect sensitive data when outsourcing to unreliable environments. It contemplates two application scenarios: a hospital and a bank. In both scenarios there are processes that are currently executed in their private infrastructures and that present a high computational or storage demand. Because they manage sensitive data, these processes cannot be outsourced directly. To solve it in WITDOM, a set of cryptographic and non-cryptographic tools are developed that allow to preserve the privacy when outsourcing these processes. Among these tools is anonymization, developed by Gradiant.
Authors: Lilian Adkinson and Pablo Dago, senior researchers in Services & Applications Department at Gradiant
References
[1] http://ec.europa.eu/justice/data-protection/reform/files/regulation_oj_en.pdf
[2] Opinion 05/2014 on Anonymisation Techniques. Article 29, Data Protection Working Party
[3] Sweeney, L. (2002). k-anonymity: A model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 10(05), 557-570.
[4] Machanavajjhala, A., Kifer, D., Gehrke, J., & Venkitasubramaniam, M. (2007). l-diversity: Privacy beyond k-anonymity. ACM Transactions on Knowledge Discovery from Data (TKDD), 1(1), 3.
[5] Li, N., Li, T., & Venkatasubramanian, S. (2007, April). t-closeness: Privacy beyond k-anonymity and l-diversity. In Data Engineering, 2007. ICDE 2007. IEEE 23rd International Conference on (pp. 106-115). IEEE.
[6] Dwork, C. (2008, April). Differential privacy: A survey of results. In International Conference on Theory and Applications of Models of Computation (pp. 1-19). Springer Berlin Heidelberg.
[7] Sweeney, L., Abu, A., & Winn, J. (2013). Identifying participants in the personal genome project by name.
Source: https://t-tees.com
Category: WHY